These E -mails are unedited uncorrected, in raw form , true mails received by me and replied by me to the Sinhala Linux group There are spelling errors , grammatical errors in my part. Please bare these errors as I am doing a one man show for the people of Sri Lanka and to protect my Sinhala letters (characters).
Oh dear dear dear!!!!
You have completely forgot the SLS1134.
I quote from the introduction
Quote
INTRODUCTION
This Draft of Sri Lanka Standard has been prepared by the Sri Lanka
Standards Institution and is now being circulated for technical comments to all
interested parties.
All comments received will be considered by the SLSI and the draft if
necessary, before submission to the Council of the Institution through the
relevant Divisional committee for final approval.
The Institution would appreciate any views on this draft which should be sent
before the specified date. It would also be helpful if those who find the draft
generally acceptable could kindly notify us accordingly."
unquote
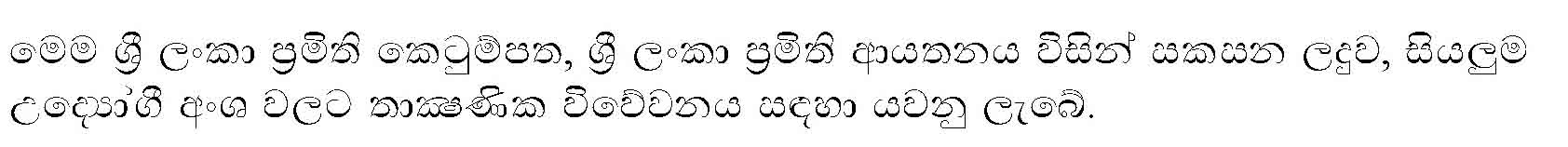
When SLSI requested public to send their comments WHY should the public apologise!!! You should apologise in public for asking public to apologise --- best joke for the year 2004!!! :-)
Even before the National Standared was made SLSI decided 128 locations and was registered in unicode as Sinhala
This is wrong act done by the side of SRI LANKA.
First we have to correct the SLSI in National LEVEL.
You spoke of two sets which are registered in Unicode (sinhala 0d80-0dff) +general punctuation 200C-200D
Also you are speaking of Set C.... Set N as an UNION of SETS
I did made my objection to the above draft and SLSI have not sent me a firm reply. My objections remain firm and valid.
With the SLS1134 one cannot use OCR , SMS , Voice to text , Text to Voice , unable to sort data in correct sinhala alphabatical order etc etc. TV and News papers made some comments and someone made them not to publish any article giving technical commnets on SLS 1134. I had no choice but to publish in www. akuru.org.
SLSI 1134 is incorrect as the figure one contain only limited number of Sinhala chaacters which is 0d80-0dff .
It is up to you to prove that SLSI is correct and Unicode (sinhala 0d80-0dff) contain all the available Sinhala Characters
If you do have any set or sets other than the 0d80-0dff & 200C-200D it is only for private use.
We got to correct the National Stadarded to protect the Sinhala Lanuages.
Unconditionally Sri Lanka National Standard has to be corrected.
Once this is done Nationally we can apply for Unicode registration.
Best
Donald
harshula wrote:
>On Tue, 2004-12-07 at 01:40 +0600, donald gaminitillake wrote:
>
>
>>Dear Harshula
>>
>>
>
>
>
>
>>Therefore unconditionally you have to redo the SLSI.
>>
>>Please admit there are errors which has to be corrected.
>>
>>
>
>Hi Donald,
>
>If we can show you why you are wrong in saying SLS 1134 is incomplete,
>will you publicly admit your error and apologise?
>
>Regards,
>Harshula
>
>
>
>>Best
>>
>>Donald
>>
>>
>
>Hi Donald,
>
>Before we continue any further, please answer these two questions with
>an explanation.
>
>1) Can 0d85 encode a single Sinhala letter?
>
>2) Can 0d9a0dcf encode a single Sinhala letter?
>
>First say 'yes' or 'no' then explain why.
>
>Donald said: "This is where the problem is. All characters need
>individual locations as done in past Mono type etc. (see letter press
>lead characters)"
>
>No Donald, like I said before, this may have been the case a few decades
>ago, but it's not the case anymore. I am more than willing to explain
>this to you, but you have to be prepared to listen and participate by
>answering the two simple questions I asked.
>
>Regards,
>Harshula
>
>
Dear Anuradha Harshula Manju and The Professor
I do have this document and I have filed objection to this document.
Everything is condenced to figure one which you will never want talk.
Figure one is wrong it is incomplete UNICODE
also you talk of 200d which are joiners but where are the other characters!!!!
You always avoid this question.
you spoke of set c and set d
I know Linux has gone further than the incomplete UNICODE but we got to correct this.
publish the letters in the set c and D correcting the SLS 1134
It may go in for several pages similar to figure one
This is the full unicode for Sinhala
At least you have admitted that Sinhala UNICODE is incomplete. ( I am happy)
Once proved incomplete --- we got to correct it and amend it.
I do have all the sinhala characters technically little over 1660 with the badhi akuru
In my system your INDRA are located as two characters two different fixed addresses
I am trying to publish this table soon.
Using that table you will be able to write any word and also the software makers will be able to make many wonders to help the Srilanka to move forward in ICT
To access this will be done using QWERTY or someone can develop for wijesekara a driver with our recomendation
I have told Manju to look into this option and still awaiting a reply from him.
Sometime next week after discussing with Mr Delan We may be able to show you the prelist
There are two problems in the sorting order of Sinhala
Some go by word Ankura comes before aa
But some takes An to the end.
Second there are two new characters introduced recently by JB Dissanayake
For the sorting order where should we keep these two
These things should be openly discussed and amicably to be kept in a location
Also the public do have the right to introduce more new characters No one can delete any!!! but my set is based on the maharagama Sammatha Sinhala Akshara malawa
All these are listed in the Akuru.org. ---- other than the full list
This problem is there for all indic languages (that is why there is no OCR SMS Voice to text so on)
Devanagari and Bengali are redoing the table
Hindi will be the first to follow the individual characters
Korean had to redo the system, Arabic too re did the table
There is an enormous potential for the Sri Lanka IT industry once I do this table and the software to go with it.
Please remember I have the full copyrights and a pending patent
For the next three days I am out of the cyber world
Wish you all a Merry Chrismas!!
Best
Donald
====================================================
Dear Donald,
For a moment, can you please stop being emotioinal and shall we discuss facts?
You have only reviewed the sinhala allocation table in Unicode. We
have gone furthur and implemented it. And we didn't find any problems
in producing any Sinhala character.
Please tell me how one can produce the words in the attach image using
the 1660 characters (or glyphs) in your proposed "solution"? We have
already done it using Unicode. And I know that other implementors
(not only SInhala, but other languages in the region) also have not
come acoss problems when implementing Unicode.
Requesting to put all the shapes into Unicode is like asking to put
all the molecules into the periodic table!
Please let me or Harshula know if you have problems understanding the
math of the set theoretic explaiation of Unicode.
Hope you will read this mail with an open mind.
Anuradha
On Tue, 07 Dec 2004 15:43:37 +0600, donald gaminitillake
<semage@mail.ewisl.net> wrote:
>>
>> Simple example is Hydrogen + oxygen gives us water.
>>
>> We have all these three elements.
>
>
See, you have misunderstood again. Hydrogen and Oxygon are elements
and Water is not: it's a molecule, and you get only the first two in
the Periodic table, not water. Nobody wants to have water in the
periodic table!
I have attached SLS 1134 to this mail if you haven't seen it already.
Please talk about the whole document, not about just one page
containing that table for allocating single code points.
Anuradha
Dear Anurudha , Harshula , Manju and the Professor
Simple example is Hydrogen + oxygen gives us water.
We have all these three elements.
Likewise your Sinhala incomplete Unicode + general punctuation = ??? (Set C and Set D)
where is Set C and Set D ??? Give me in images and locations in unicode or in SLS
What are the address of Set C and Set D? what is the first location character of set C? where it start and where it ends???
There should be a matrix, chart or an table for Set C and Set D.
The SLS 1134 which is 0d80-0dff = unicode; need to be corrected including the your new Set C and Set D.
Unicodes are character allocations tables for most of the languages in this world
our Sinhala unicode location: 0d80-0dff is an incomplete set. (see http://www.unicode.org/charts)
You got to admit this and we need a correction As soon as possible
I have proved this fact without any reasonable doubt.
Also you avoid answering me about the "union"
Has this been specified in the SLS 1134 if so where????
SLS 1134 do have only 0d80-0dff (incomplete Sinhala)
unicode general punctuation = 200C-200D
I have sent you both pdf files.
I am from the Printing and Publishing Industry where charaters (letters) belongs.
I have not misquoted anything in akuru.org.
It is the truth without any fear or favour.
I have only given a link to the document and highlighted few lines.
If you have the courage and a back bone why not translate it correctly and publish in Sinhala News Papers and TV and see the public responce!!!
Your group have blocked the local media to distroy Sinhala Language.
Do not distroy my Sinhala!!!!!
For the betterment of Sri Lanka we all got to correct the SLS 1134 unconditionally and ASAP
best
Donald
Anuradha Ratnaweera wrote:
>On Tue, 07 Dec 2004 01:40:38 +0600, donald gaminitillake
><semage@mail.ewisl.net> wrote:
>
>
>>
>> Let me have the Set C and D from unicode.
>>
>>
>
>Set C and set D are derivatives of set A and set B. Please see the
>following technical report from Unicode consortium about the way they
>are generated. It talks about unions and subsets you wanted a link
>for.
>
> http://www.unicode.org/reports/tr17/tr17-5.html
>
>I think you are confused glyphs, characters and code points. Please
>read this article if you haven't done it already:
>
> http://www.unicode.org/standard/where/
>
>
>
>>Your Union is not listed. I enclose the pdf files from unicode for your
>>perusal.
>>
>>
>
>If you look at basic set theory, either a set can be defined by
>listing out all its elements (e.g.: set A and set B above), or by
>defining the way it is generated. The technical report above explains
>how this definition is done, and the paper by Dr Gihan and Aruni -
>which you have kind of miss-quoted on www.akuru.org - defines them for
>Sinhala specifically.
>
> Anuradha
>
On Tue, 7 Dec 2004 10:52:41 +0600, Anuradha Ratnaweera
<gnu.slash.linux@gmail.com> wrote:
>>
>> I think you are confused glyphs, characters and code points. Please
>> read this article if you haven't done it already:
>>
>> http://www.unicode.org/standard/where/
>
>
Quoting a complete paragraph from the above text:
"The character you are looking for may be represented as a sequence of
code points in Unicode. Here are examples of such characters, and
their representation as a sequence of code points."
Anuradha
>
>
>
>Dear Harshula
>
>
>
>SINHALA LETTER AYANNA = 0d85
>
>
>
>sinhala letter ka = 0d9a
>
>
>
>In your system with a joiner (in set B) + 0dcf AELA-PILLA and get "KA"
>
>
>
> "Dumriya" train :: with the set a you cannot get DU or RI correctly
>
>
>
>SLS 1134 does not talk of a "UNION" BUT Unicode 0d80-0dff
>
>
>
>Can you show me a document in SLSI where they define SLS1134 as a Union
>and gives all the locations.
>
>(even a photo copy of a page would do if you can send as an image)
>
>
>
>Now show me where is set C and D located in the unicode or in SLSI so
>that I can download as a pdf
>
>
>
>This is where the problem is. All characters need individual locations
>as done in past Mono type etc. (see letter press lead characters)
>
>
>
>Then you can have more Majic in Sri Lankas ICT.
>
>
>
>Best
>
>
>
>Donald
>
>
>
>
>harshula wrote:
>
>
>
>>On Mon, 2004-12-06 at 19:54 +0600, donald gaminitillake wrote:
>>
>>
>>>Dear Harsshula
>>>
>>>
>>>I am Still at the same place: ( as you wrote -- word by word)
>>>
>>>SLS 1134 = Unicode 0d80-0dff locations (this is a the incomplete
>>>sinhala alphabet)
>>>
>>>Is this correct?
>>>
>>>
>>
>>Hi Donald,
>>
>>Absolutely not!
>>
>>SLS 1134 is the union of:
>>
>>Set A = Set A1 Union Set A2 Union Set A3 = 0d80-0dff
>>
>>Set B = 200C-200D
>>
>>Set C = Cartesian product of A2 and A3
>>
>>(Set C2 = Union of C and A2)
>>
>>Set D = a subset of the Cartesian product of B, A3, A2 and C2
>>
>>
>>
>>
>>>I find your "set b" contains General Punctuation Range: 2000–206F
>>>this include
>>>
>>>
>>
>>No. Set B does not contain general punctuation.
>>
>>As I stated in my previous email:
>>"Set B consists of two elements, the magical ZWNJ and ZWJ"
>>
>>When I say that Set B consists of two elements, why would list all these
>>other unrelated elements. Set B consists of TWO elements, ZWNJ and ZWJ.
>>
>>Before we continue any further, please answer these two questions with
>>an explanation.
>>
>>1) Can 0d85 encode a single Sinhala letter?
>>
>>2) Can 0d9a0dcf encode a single Sinhala letter?
>>
>>
>>Regards,
>>Harshula
>>
>>
>>
>>
>>>Spaces , Dashes,EM SPACE FOUR-PER-EM SPACE DOUBLE VERTICAL LINEs
>>>etc , LINE SEPARATORs , PER MILLE SIGN etc , DOUBLE DAGGERs etc,
>>>QUESTION EXCLAMATION MARKs etc, COMMERCIAL MINUS SIGNs etc ,
>>>REVERSED SEMICOLON etc. QUADRUPLE PRIME, Greek enotikon, Urdu
>>>paragraph separator .Japanese kome, INVISIBLE SEPARATOR etc and
>>>
>>>Formatting characters
>>>200C ZERO WIDTH NON-JOINER
>>>= ZWNJ
>>>200D ZERO WIDTH JOINER
>>>= ZWJ
>>>200E LEFT-TO-RIGHT MARK
>>>= LRM
>>>200F RIGHT-TO-LEFT MARK
>>>
>>>Where are the unicode locations and/or SLSI locations for sinhala
>>>language byond this?
>>>
>>>Which you refers as Set C = Cartesian product of A2 and A3 & Set D =
>>>a subset of the Cartesian product of B, A3, A2 and C2
>>>
>>>Can you give me the similar locations to download from UNICODE.
>>>
>>>I will be in and out of Colombo during the next fewe days and E mails
>>>may get delayed
>>>
>>>Best
>>>
>>>Donald
>>>
>>>
>>>
>>>
>>>harshula wrote:
>>>
>>>
>>>>Hi Donald,
>>>>
>>>>Set A = Set A1 Union Set A2 Union Set A3 = 0d80-0dff
>>>>
>>>>Set B = 200C-200D
>>>>
>>>>Set C = Cartesian product of A2 and A3
>>>>
>>>>(Set C2 = Union of C and A2)
>>>>
>>>>Set D = a subset of the Cartesian product of B, A3, A2 and C2
>>>>
>>>>You seem to be very interested in Set B, so I assume you already
>>>>understand and acknowledge Set C, as it's derivable from Set A2 and A3.
>>>>
>>>>Set B consists of two elements, the magical ZWNJ and ZWJ:
>>>>http://www.unicode.org/charts/PDF/U2000.pdf
>>>>
>>>>Regards,
>>>>Harshula
>>>>
>>>>
>HOME>